EPFL Master Thesis - spring 2020
Energetic, Environmental and Economic Model of a Farm: Case study Swiss Future Farm (This Master project was completed as of 24.09.2020 and recieved the maximum grade)
Author’s previous work (cited in thesis) Nils Ter-Borch Semester Project EPFL - Cleaning of biomass derived gasses for Solid Oxide Fuel Cell applications (2020) Supplement 1 Supplement 2 Supplement 3
Optimization tool: Gurobi - Academic Licencs
Support for writing the optimization problem: Gurobipy - Python - Anaconda - Spyer 4

Results visualization
Results of the OPEX - CAPEX optimization for the default scenario B using 10 typical days
Link to OPEX-CAPEX parallel coordinates graph
Results of the ENVEX - TOTEX optimization for the default scenario B using 10 typical days
Link to ENVEX-TOTEX parallel coordinates graph
Results of the ENVEX - TOTEX optimization for scenario C using 10 typical days
Link to “No Wood Boiler” ENVEX-TOTEX parallel coordinates graph
Results of the ENVEX - TOTEX optimization for scenario D using 10 typical days
Link to “Cheap PV” ENVEX-TOTEX parallel coordinates graph
Results of the ENVEX - TOTEX optimization for the scenario G using 10 typical days
Link to “Palezieux” ENVEX-TOTEX parallel coordinates graph
Results of the Tariff - TOTEX optimization for the scenario G using 10 typical days
Link to Feed-in Tariff-TOTEX parallel coordinates graph
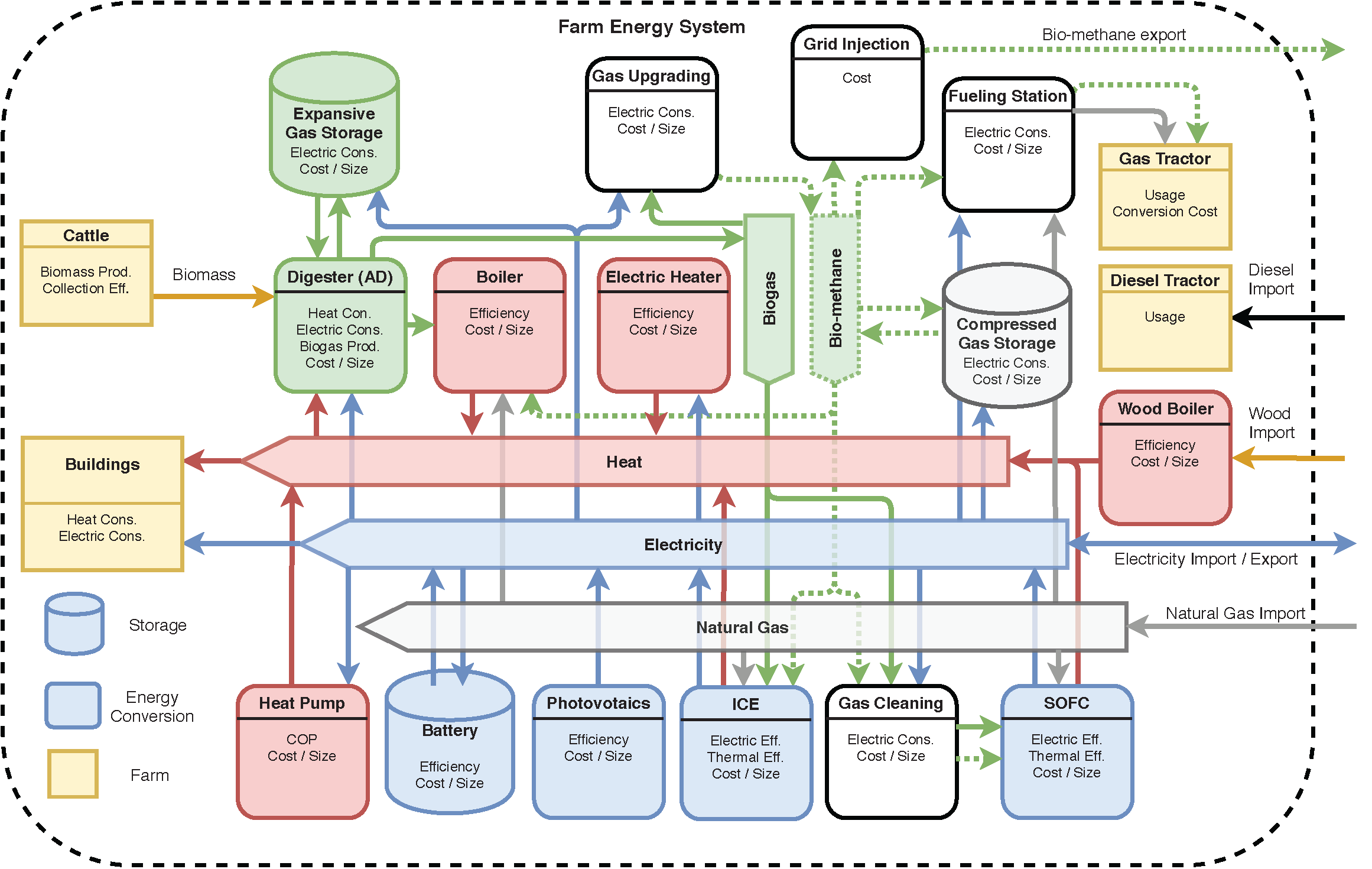
Farm Energy System user guide
The Farm Energy System (FES) was developed with the programming language Python, using the Gurobi-python module provided by the Gurobi optimization software under academic licence. The FES model is available at https://github.com/terborch/SFF and is free to use or modify, provided a licence for Gurobi can be obtained by the user. Feel free to contact me via GitHub and get my permission to branch this project. This user guide will give a short overview of the model structure in terms of folders, files and functions, then give a couple examples of how the FES could be used. Files that are not mentioned by the guide are not necessary to the default FES model.
A foreword regarding the python code. It follows some but not all PEP8 guidelines. Comments where added to most functions and modules to describe them. The unit abbreviations are the same as in the report. When in doubt, all abbreviations are directly available in the global_set.py module. The first letter of parameters, dictionaries and lists is an upper case letter to distinguish them from Gurobi variables which all start with a lower case. Python functions start with a lower case as per PEP8. Each of the model equation has a number in the C_meta dictionary that corresponds to the equation number in the project report. Link to thesis
Description of the essential files and folders
The GitHub root directory or “Origine” contains mostly project metadata that can be safely ignored and the folder sff_mip which contains the FES in the form of 9 .py files. The FES receives input data and settings located in the inputs folder and produces outputs stored in the results folder (This folder may have to be manually created by the user, since it is not shared on GitHub due to its size.)

Concerning inputs, settings.csv controls the solve time limit, variable bounds and may be used to activate or deactivate units. Unit performance parameters are stored in parameters.csv, cost and emissions related parameters are stored in cost_param.csv, while parameters that where pre-calculated are stored in either calc_param.csv (signle values) or inputs.h5 (time dependent values). The profiles folder, animals.csv, heat_load_param.csv and clusters.h5 contains parameters only relevant to the pre-calculation and not the FES per-say.
Concerning outputs, they will be saved (according to specifications by the user) to a daily year-month-day folder, inside results.
The global_set.py module declares global sets of Units, and what each unit consumes, produces or stores as well as Resources and which are exchanged with the grids. This module has no local dependencies.
The data.py module declares a number of data handling related functions used in all other modules to read parameter values from input files, read weather data, modify input files or pass data from one format to another. Generally this module contains functions that are use full for multiple modules. This module has no local dependencies.
The clustering.py module is used to cluster weather parameters using a k-means algorithm and write the resulting cluster-mediod index to the clusters.h5 file.
The write_inputs.py module handles the pre-calculation. It transforms weather data according to the selected clustering, calculate the electric load profile, the biomass energy and emissions potentials and fueling profile, saving all time dependent inputs to inputs.h5 and signle values to calc_param.csv.
The heat_load_param.csv module is only called by write_inputs.py to generate the heat load profile of the buildings and the AD, also stored in inputs.h5.
The read_inputs.py module will read the settings, parameters and profiles from settings.csv, parameters.csv, cost_param.csv, calc_param.csv and inputs.h5 and pass them on for the model description.
The model.py module calls all functions necessary to describe and solve the FES model. It receives the inputs from read_inputs.csv and global_set.py. It initializes the MILP model called m. It calls on variables.py to initialize the model variables. It fixes unit size bounds according to settings.csv. It calls on units.py to model each unit. It describes the energy balance. It describes the objective functions. It describe basic scenarios for multi objective solving and a function run that when called will solve the optimization problem.
The variables.py module declares all the unit related variables according to the sets from global_set.py.
The units.py module describes one by one each unit, each in its own function.
The run.py module is used to solve the FES model once or multiple times, using default or custom settings regarding inputs, objectives, and outputs. Its run function will solve the model once along a given objective and store the solution results into a new folder. Its pareto function will solve the model $n$ times between two objectives, store each intermediary solution in single folder along with the relevant graphs.
The results.py model is called by run.py to store the model solution to a results.h5 file. Data in results.h5 can be read to three pandas dataframes called ‘Single’ for 0D single value results, ‘Daily’ for 2D daiy-hour format results and ‘Annual’ for 1D hourly results (only the SOC of storage units). The module also contains functions related to automatic folder creation for results.
The results.py model is called by run.py to plot graphs of all kind. Alternatively graphs of inputs may be directly generated by this module.
Example: Adding a unit to the model
Adding a a technology to the model should not take more than $10min$ once the user has gathered cost and performance parameters and decided on a mathematical description. For this example we will add a simple thermal solar panel unit with an efficiency only.
- Chose an abbreviation, e.g. TS
- Add the efficiency to
parameters.csvand the related costs tocost_param.csv - Add the unit to the tuple Units in
global_set.py - Add the unit and the resource it consumes and produces to the dictionaries U_cons and U_prod, execute
global_set.pyand check that U_res contains the right information for TS. Use the existing PV for comparison. - Create a new function in
units.pycalled ts and describe the unit using the Gurobi python (The online Gurobi documentation is available at url{https://www.gurobi.com/documentation/9.0/. I highly recommend using it extensively and trying a few of their examples.) and the new variables that where automatically generated by changingglobal_set.py`. Since the TS is similar to the PV, simply copy the pv function and change the relevant information. Use the pandas series P to access the unit parameters you entered into the .csv files. - In
model.py, call the function you just wrote with units.ts(…) inside of the model_units function. - Execute the
model.pymodule to check for errors. - Make sure the unit is part of the right energy balance, in this case it produces heat only and will be automatically added to the right constraint if it is part of the Heat subset in the U_prod set. And keep in mind all other technologies produce and consume in $kW$-resource.
- Execute a single run in the
run.pymodule with ‘envex’ as the objective. If the TS does not appear in the results, try constraining its size to any reasonable value inside of thesettings.csvfile to force it to be installed.
Debugging
MILP modelling is complicated. In my (short) experience with Gurobi, I have encountered my fair share of “model infeasible”, here is how I dealt with them. Look up the last function in run.py, it may be usefull.
The best practice to avoid problems is to code in small chunks. Write down on paper exactly what you want before you code it. For every single change you make to the model, make a run and check the solution to catch problems early. Problems only occur after something has been modified, so make sure not to to many modifications at once or else it will be very complicated to walk back and find the problem.
When Gurobi throws “model infeasible” error, it could often be solved by relaxing the setting Bound or Tight in the settings.csv file. Then searching for a variable with a large value will allow you to find the culprit. This error usually comes from an error in a constrain or a confusion with physical units e.g. Watt instead of kW.
When Gurobi solves for over 1’000s under a 10 typical days temporal clustering, something has gone wrong. If the console does not write “Warning…” messages, the problem is likely due to an unconstrained objective, that can get smaller and smaller while many variables reach their Bounds due to an error in the model description. Use a short limit on the solve time, e.g. 100s to terminate the solving process early. Gurobi will return a premature solution. Use it to look for large variables and identify your problem. (Usually, when the number of unexplored nodes keep increasing, the solution is nowhere near)
When Gurobi solves for long times, and or the solutions look weird the problem may come from numerical errors. Some “Large M variables” constrain binary variables to continuous variables. These constraints can be violated if the Bounds (Bound or Tight in the settings.csv file) become too large compared to the continuous variable they constrain (See the Gurobi documentation on numerical errors). The solver should also start throwing warning while solving. The solution to this problem is to keep the bounds as low as possible (less than 100 for Tight and 10’000 for Bound) by changing reformulating the problem.
A note on performance. The performance of the FES model and its observed solve time without the use of clustered time periods is not acceptable. This is most likely due to a large difference of scale in the coefficient matrix. The smallest coefficient is on the order of $10^-8$ while the largest, the upper bound $M$ is on the order of $10^3$. This will cause numerical issues for the solver and slow down the optimization. A rescaling of some of the model variables will often solve this problem and could greatly enhance the performance of the FES.
How To install and run the module.
This module was created on windows 10 using Spyder 4 from Anaconda. It should run on Mac and Linux as well but this has not been tester (i.e. all path declaration uses os.path.join)
-
Install anaconda https://www.anaconda.com/distribution/
-
Run the anaconda command consol
-
Get a Gurobi licence (registration with academic email requiered) and install it on your machine
-
Run
conda config --add channels http://conda.anaconda.org/gurobiin the anaconda consol -
Then run
conda install gurobito install the gurobi module that can now be imported into python withimport gurobipy as gp -
Run Spyder (or any other IDE you’d like) using the command
spyderin the consol
Alternatively use a specific anaconda environment but this module can be used in the (base). Navigate to the module folder sff_mip in the consol .Install anaconda the environment sff_mip using the provided .yml file (only few external packages are used) and the following command: conda env create -f environment.yml. Activate the environment using this command: conda activate sff_mip.
MIT open source software licence
Copyright (c) 2020 nils ter-borch
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.